OCR-工业字符检测实践
1. PaddleOCR
- 使用PPOCRLabel标注,完成自定义训练数据集的准备;
- 训练文本检测模型;
- 训练文本识别模型;
- 训练模型转换为inference模型;
- 基于python引擎的PP-OCR模型推理预测,串联检测+识别。
2. PPOCRLabel
PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注和四点标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
使用步骤:
- cd ./PPOCRLabel
- python .\PPOCRLabel.py —lang ch
- 打开待标注文件夹,加载标注图像
- 勾选 文件/自动导出标记结果
- 标注
- 导出识别结果(切小图)
Bounding Box Regression Loss
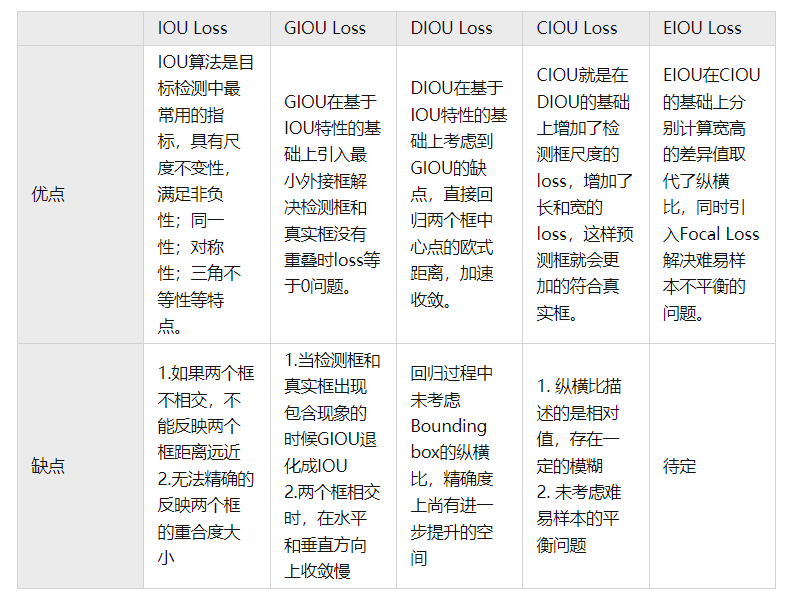
RoI Pooling, RoI Align, PS-RoI Pooling
1. RoI
RoI(Region of Interest), 从原图中通过某些区域选择方法得到的候选区域。
量化(quantization)是指将输入连续值(或者大量可能的离散值)采样为有限多个离散值的过程。或者理解为,将输入数据集(如实数)约束到离散集(如整数)的过程。
RoI Pooling 和 RoI Align 均是将任意大小的特征图(输入),映射为固定尺寸的特征(输出)。
2. RoI Pooling
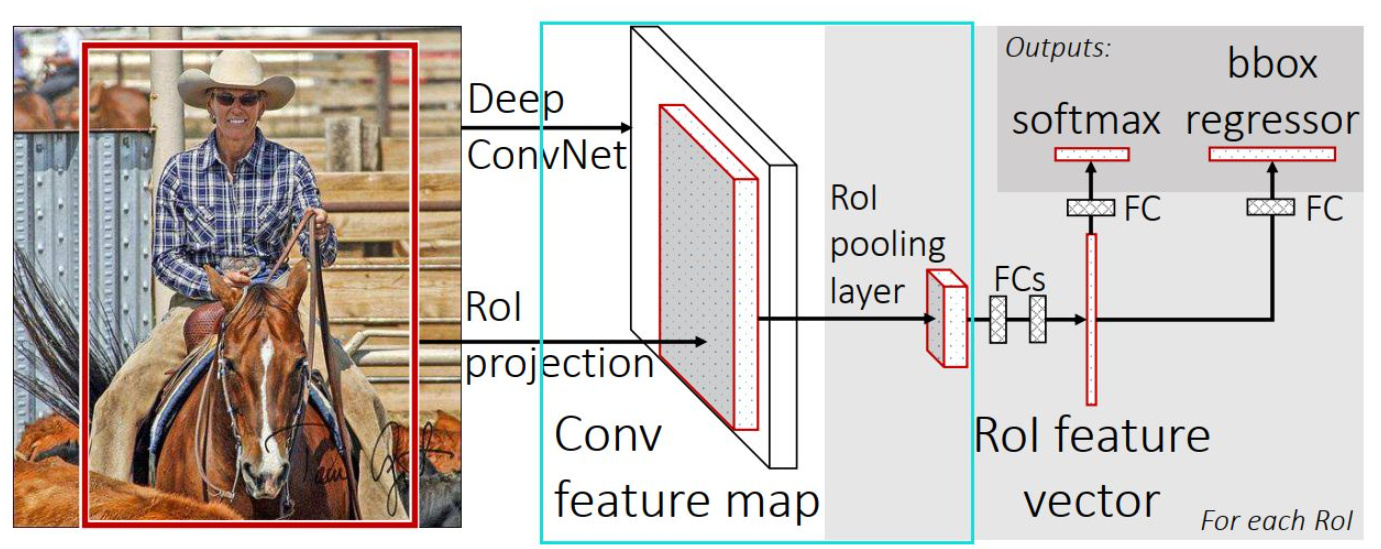
RoI Pooling的作用本质上是为了将不同尺寸的RoI特征转换为相同的特征图输出,保证特征图展开(flatten)后具有相同的大小尺寸,能够与下层的全连接层连接,分别执行线性分类(linear classifier)和边框回归(bounding box regressor)
图像相似度计算方式
目标检测中的FPN
z 摘录自小纸屑 https://zhuanlan.zhihu.com/p/148738276
1. 简介
FPN结构,特征金字塔网络,主要用作不同尺度的特征融合,从而提高目标检测算法的精度。
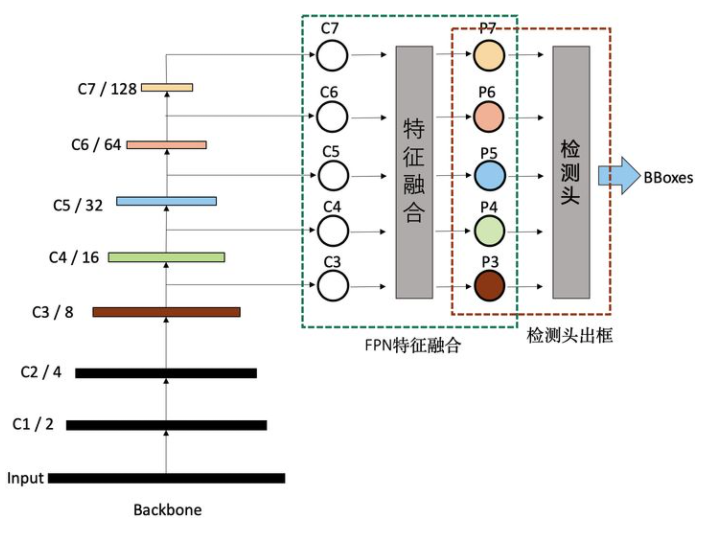
常见的物体检测算法,其实可以分解为三个递进的阶段:
Backbone特征提取阶段
Backbone生成的特征,一般按stage划分,分别记作C1、C2、C3、C4、C5、C6、C7等,其中的数字与stage的编号相同,代表的是分辨率减半的次数,如C2代表stage2输出的特征图,分辨率为输入图片的1/4,C5代表,stage5输出的特征图,分辨率为输入图片的1/32。
Neck特征融合阶段
FPN一般将上一步生成的不同分辨率特征作为输入,输出经过融合后的特征。输出的特征一般以P作为编号标记。如FPN的输入是,C2、C3、C4、C5、C6,经过融合后,输出为P2、P3、P4、P5、P6。这个过程可以用数学公式表达:
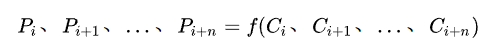
Head检测阶段
FPN输出融合后的特征后,就可以输入到检测头做具体的物体检测。
ASFF
YOLOV3-ASFF
1. 简介
YOLOV3-ASFF为了解决FPN不同特征尺度之间的不一致问题,提出自适应空间特征融合策略。它通过设置可学习权重因子对不同尺度的特征进行自适应(可学习)融合,通过在空间上过滤冲突信息从而抑制梯度反传时的不一致问题,从而改善了特征的比例不变性,也降低了时间开销。
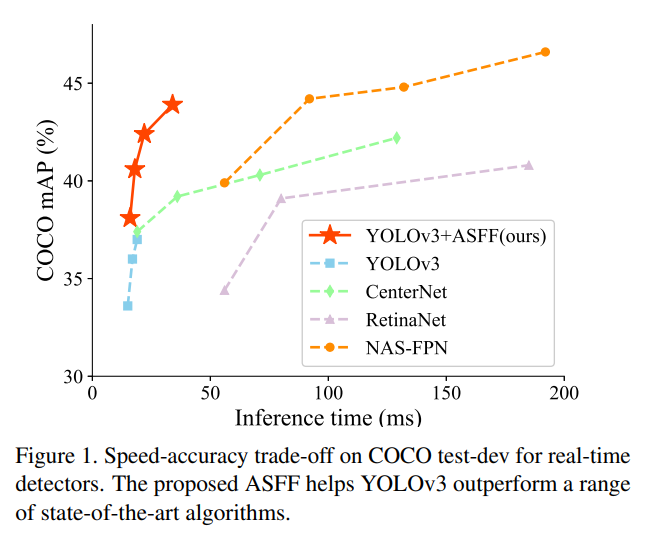
除了自适应空间特征融合,YOLOv3-ASFF在YOLOv3基础上博采众长,集合了MixUp数据增强,学习率cosine衰减策略,异步BN,Guided Anchoring,回归loss改为IoU loss等一系列tricks。 其strong yolov3-608 在COCO2017上达到了 38.8AP + 50fps的效果, 超过了原始YOLOv3-608 : 33.0AP + 53fps。
YOLOv5 自适应图片缩放
自适应图片缩放
按照以往的经验,目标检测算法在训练和推理阶段都会resize到统一的图像尺寸,YOLOv5在推理阶段采用了自适应的图片缩放trick。

在YOLOv5 官方github下有这样一段解释,采用32整数倍的矩形框推理要比resize到等长宽的正方形进行推理的时间减少很多(416 ,416)->(256 , 416)。
训练阶段
假设原图尺寸为(523, 699)
(1) 计算长边缩放比例 r = 416 / 699 = 0.5951
(2)将原图等比例缩放 (523,699) —>> (311, 416)

(3) 填充为(416,416),H侧上下需要填充的大小 pad = (416 - 311) / 2 = 52.5

C++线程锁
C++11中的几种线程锁
线程之间的锁有: 互斥锁,条件锁,自旋锁,读写锁,递归锁。一般情况下,锁的功能是与程序性能成反比。
互斥锁(Mutex)
互斥锁用于控制多个线程对他们之间共享资源互斥访问的一个信号量,为了避免多个线程在某一时刻同时操作一个共享资源。例如线程池中的有多个空闲线程和一个任务队列。任何是一个线程都要使用互斥锁互斥访问任务队列,以避免多个线程同时访问任务队列以发生错乱。在某一时刻,只有一个线程可以获取互斥锁,在释放互斥锁之前其他线程都不能获取该互斥锁。如果其他线程想要获取这个互斥锁,那么这个线程只能以阻塞方式进行等待。
1
2
3
4
5
6
7
8
9
10
11
std::list<int> some_list;
std::mutex some_mutex;
void add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex);
some_list.push_back(new_value);
}