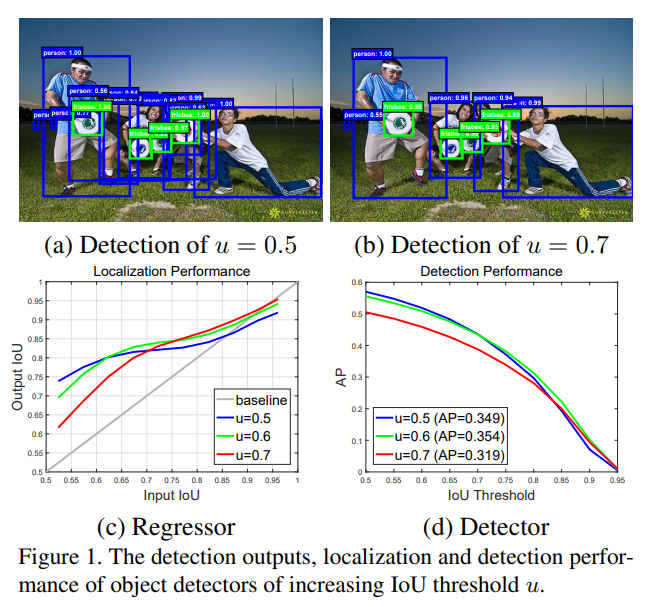
1. RetinaNet 简介
paper: https://openaccess.thecvf.com/content_ICCV_2017/papers/Lin_Focal_Loss_for_ICCV_2017_paper.pdf
code: https://github.com/facebookresearch/Detectron
RetinaNet 检测算法出自Facebook AI Research的论文 Focal Loss for Dense Object Detection, 作者包含了RCNN作者Ross Girshick、何恺明和Piotr。
主要提出了Focal Loss解决单阶段检测算法中的类别不均衡问题,(正负样本不均衡,难易样本不均衡),使得RetinaNet这个单阶段检测网络达到甚至超越了部分两阶段的目标检测网络。
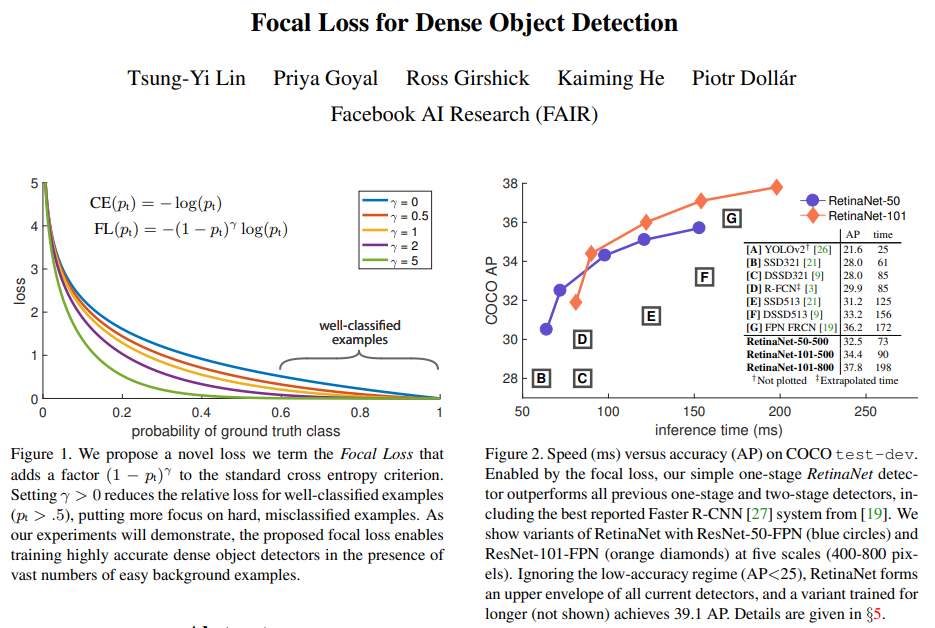
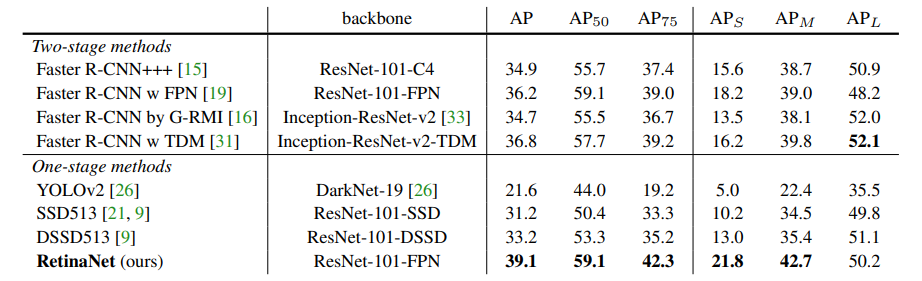
单阶段检测网络相比两阶段网络精度较差的原因很大层面是由于类别的不均衡。
单阶段在Head的特征图上会产生密集的目标候选区域,要远超RPN产生的2000个proposals。而这些proposals只有很少一部分包含目标物体,从而造成了较为严重的正负样本不均衡的问题,少量正样本提供的loss在整体loss中占比较小,影响了模型对于正样本的学习效果。
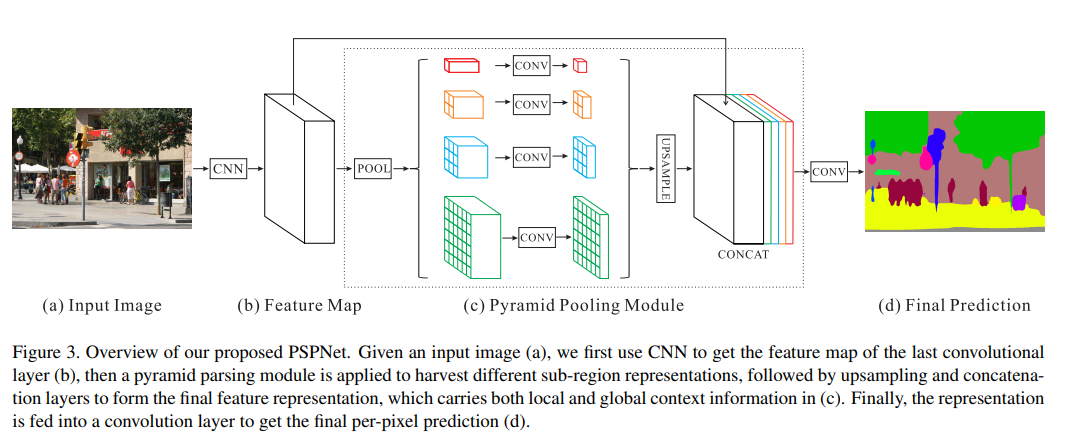
2. 网络结构
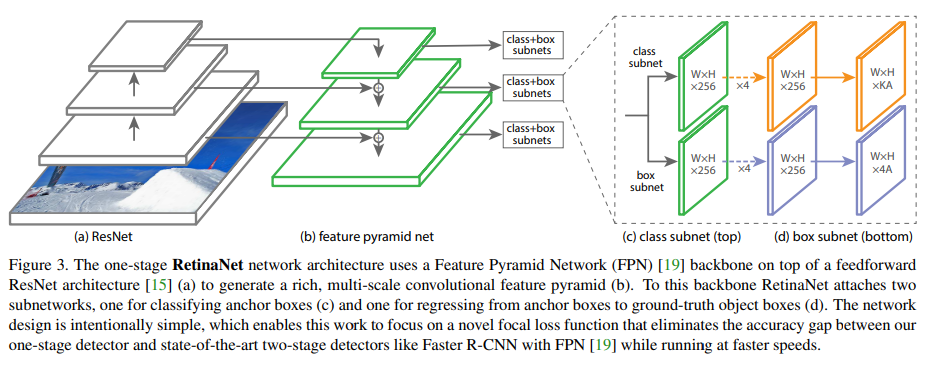
RetinaNet网络结构包含 BackBone、 FPN的Neck, 以及最后的包含两个自网络的Head部分。