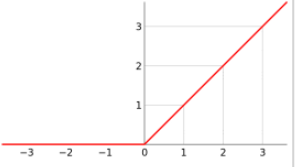
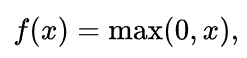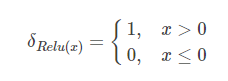L1正则和max函数的可导性 发表于 2022-05-10 分类于 deep learning , cnn backbone 阅读次数: 今天在知乎看见一个讨论L1正则函数, ReLU激活函数的可导性的问题?记录一下理解 一般情况下,深度学习在反向传播时需要对各层的函数求导数,从而向前传播梯度,那么是不是在一个神经网络中,是不是要求所有的计算op都是连续可导的呢?很明显不是这样的,例如ReLU, 很明显在0这一点处也不可导,那梯度就没有了吗,其实一般的训练框架在这种情况下,会对0这一点的梯度分配一个所谓的“sub-gradient”次梯度来代表无法求导的这个点的梯度。 例如可以将0处的导数置为0。