1. ResNest

paper: https://hangzhang.org/files/resnest.pdf
作者讲解:https://www.bilibili.com/video/BV1PV411k7ch
ResNeSt提出了Split-Attention Block模块, 其考虑到组卷积降低计算量、以及通道注意力策略提升跨通道的相互作用,可以理解为ResNeXt和SKNet的结合版。在图像分类,目标检测,目标分割等众多Backbone上有了明显提升。

2. Split-Attention Block
1.先对输入特征,分为k个Cardinal Groups,每个Cardinal Group分为r个radis的子特征
2.对分离的每个组进行 1 x 1 + 3 x 3卷积,得到每个h x w x c的特征
3.对2中得到的特征进行sum操作,得到尺寸为h x w x c的特征
4.对3中特征进行F.adaptive_avg_pool2d操作,得到1 x 1 x c的特征
5.对4中特征,进行两个FC操作,得到1 x 1 x r*c的特征
6.进行r-softmax(对每个1x1xc个特征进行softmax),再分别与r个组进行点乘操作,即为注意力赋值相加
7.与Input进行skip-connect
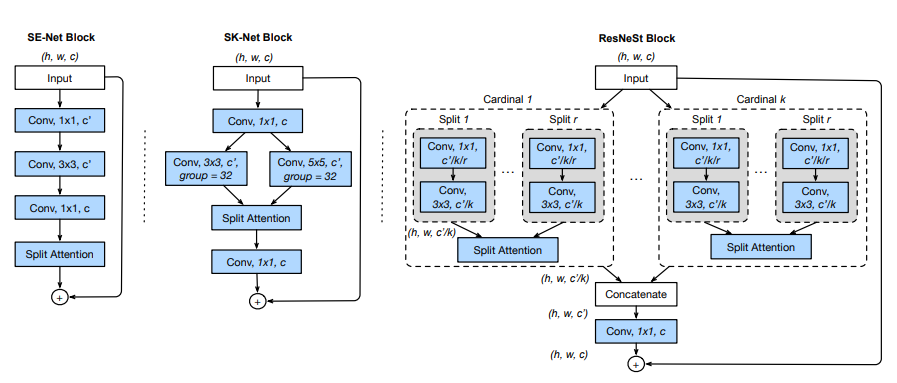
借鉴ResNeXt模型的思想,将Input Tensor分为K组,记为Cardinal k, 然后将每个Cardinal 拆分为r个子模块, 记为Split r。 整个Resnest Block有G = k x r 组。
每个Split 模块中首先经过1x1、3x3卷积生成通道为c/k的特征图, 然后r个split模块的输出特征图进入Split Attention获得通道加权后特征图,再将各个cardinal的输出特征图concat到一起。
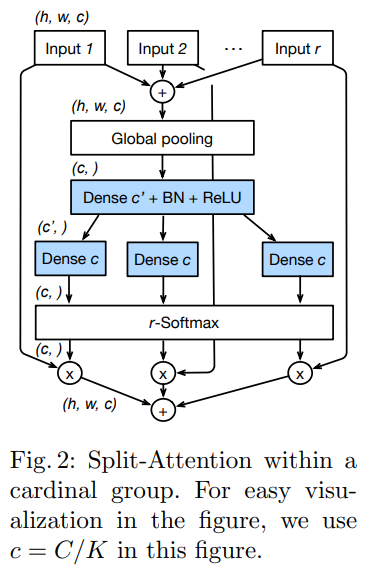
split-attention 模块的具体结构如上图所示,主要实现代码如下图所示,有大佬进行了注释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120"""Split-Attention"""
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn import Conv2d, Module, Linear, BatchNorm2d, ReLU
from torch.nn.modules.utils import _pair
__all__ = ['SplAtConv2d']
class SplAtConv2d(Module):
"""Split-Attention Conv2d
基数cardinality =groups= 1 groups对应nn.conv2d的一个参数,即特征层内的cardinal组数
基数radix = 2 用于SplAtConv2d block中的特征通道数的放大倍数,即cardinal组内split组数
reduction_factor =4 缩放系数用于fc2和fc3之间减少参数量
"""
def __init__(self, in_channels, channels, kernel_size, stride=(1, 1), padding=(0, 0),
dilation=(1, 1), groups=1, bias=True,
radix=2, reduction_factor=4,
rectify=False, rectify_avg=False, norm_layer=None,
dropblock_prob=0.0, **kwargs):
super(SplAtConv2d, self).__init__()
# padding=1 => (1, 1)
padding = _pair(padding)
self.rectify = rectify and (padding[0] > 0 or padding[1] > 0)
self.rectify_avg = rectify_avg
# reduction_factor主要用于减少三组卷积的通道数,进而减少网络的参数量
# inter_channels 对应fc1层的输出通道数 (64*2//4, 32)=>32
inter_channels = max(in_channels*radix//reduction_factor, 32)
self.radix = radix
self.cardinality = groups
self.channels = channels
self.dropblock_prob = dropblock_prob
# 注意这里使用了深度可分离卷积 groups !=1,实现对不同radix组的特征层进行分离的卷积操作
if self.rectify:
from rfconv import RFConv2d
self.conv = RFConv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation,
groups=groups*radix, bias=bias, average_mode=rectify_avg, **kwargs)
else:
self.conv = Conv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation,
groups=groups*radix, bias=bias, **kwargs)
self.use_bn = norm_layer is not None
if self.use_bn:
self.bn0 = norm_layer(channels*radix)
self.relu = ReLU(inplace=True)
self.fc1 = Conv2d(channels, inter_channels, 1, groups=self.cardinality)
if self.use_bn:
self.bn1 = norm_layer(inter_channels)
self.fc2 = Conv2d(inter_channels, channels*radix, 1, groups=self.cardinality)
if dropblock_prob > 0.0:
self.dropblock = DropBlock2D(dropblock_prob, 3)
self.rsoftmax = rSoftMax(radix, groups)
def forward(self, x):
# [1,64,h,w] = [1,128,h,w]
x = self.conv(x)
if self.use_bn:
x = self.bn0(x)
if self.dropblock_prob > 0.0:
x = self.dropblock(x)
x = self.relu(x)
# rchannel通道数量
batch, rchannel = x.shape[:2]
if self.radix > 1:
# [1, 128, h, w] = [[1,64,h,w], [1,64,h,w]]
if torch.__version__ < '1.5':
splited = torch.split(x, int(rchannel//self.radix), dim=1)
else:
splited = torch.split(x, rchannel//self.radix, dim=1)
# [[1,64,h,w], [1,64,h,w]] => [1,64,h,w]
gap = sum(splited)
else:
gap = x
# [1,64,h,w] => [1, 64, 1, 1]
gap = F.adaptive_avg_pool2d(gap, 1)
# [1, 64, 1, 1] => [1, 32, 1, 1]
gap = self.fc1(gap)
if self.use_bn:
gap = self.bn1(gap)
gap = self.relu(gap)
# [1, 32, 1, 1] => [1, 128, 1, 1]
atten = self.fc2(gap)
atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
# attens [[1,64,1,1], [1,64,1,1]]
if self.radix > 1:
if torch.__version__ < '1.5':
attens = torch.split(atten, int(rchannel//self.radix), dim=1)
else:
attens = torch.split(atten, rchannel//self.radix, dim=1)
# [1,64,1,1]*[1,64,h,w] => [1,64,h,w]
out = sum([att*split for (att, split) in zip(attens, splited)])
else:
out = atten * x
# contiguous()这个函数,把tensor变成在内存中连续分布的形式
return out.contiguous()
class rSoftMax(nn.Module):
def __init__(self, radix, cardinality):
super().__init__()
self.radix = radix
self.cardinality = cardinality
def forward(self, x):
batch = x.size(0)
if self.radix > 1:
# [1, 128, 1, 1] => [1, 2, 1, 64]
# 分组进行softmax操作
x = x.view(batch, self.cardinality, self.radix, -1).transpose(1, 2)
# 对radix维度进行softmax操作
x = F.softmax(x, dim=1)
# [1, 2, 1, 64] => [1, 128]
x = x.reshape(batch, -1)
else:
x = torch.sigmoid(x)
return x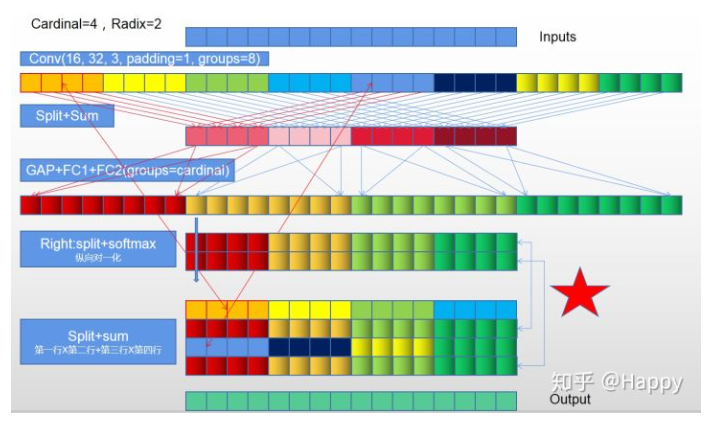
借鉴知乎大佬@Happy的理解示意图。