1. Cascade R-CNN 提出的背景
paper: https://arxiv.org/pdf/1712.00726.pdf
算法针对的背景问题如下:
在RCNN框架的目标检测中,通过目标框和检测框之间的IoU(Intersection over union)来划分正负样本,会面临几个问题。
- 使用较低的IoU阈值,会有众多背景框参与训练,影响目标框的检测效果,带来干扰的噪声。
- mismatch问题,由于IoU阈值的筛选,training阶段的proposals质量更高,而inference阶段未经过筛选,所以proposals质量则相对较差,
- 使用较高的IoU阈值,高质量检测框数量减少,网络训练时容易过拟合,
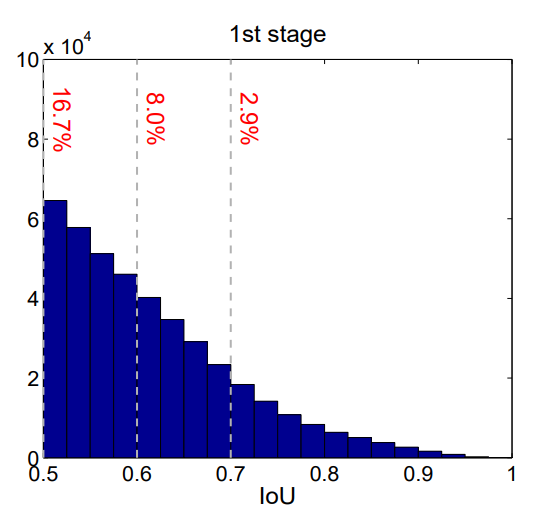
上图标识RPN输出的proposals在各个IoU范围内的数量分布,可以看到随着IoU阈值的提高,相对应的proposals数量逐渐减少。
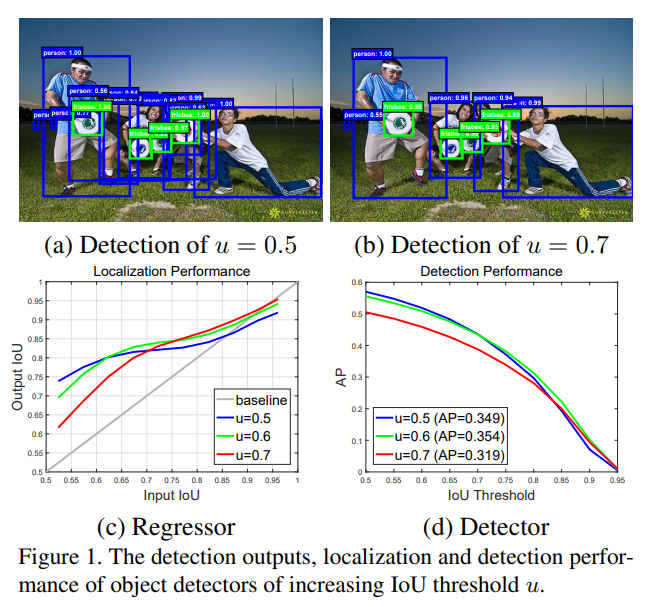
上图(c),横轴 Input IoU 表示 RPN 输出的 proposal 与 gt bbox 的 IoU,纵轴 Output IoU 是经过 RCNN 的 bbox 分支回归输出后与 gt bbox 的 IoU,不同线条代表不同阈值训练出来的 detector。以 u=0.5 为例,当对 RPN 输出的 proposal 使用阈值 0.5 来切分正负样本,对于那些 bbox 质量较差(也算正样本,0.5 < Input IOU < 0.55), 经过 R-CNN 回归后效果提升明显,IoU 可以直接回归到 0.75 (和正样本分布有关系,在该区间内的正样本比较多),且随着 proposal 质量增加,RCNN 回归后的 bbox 质量也会增加,但是 Input IoU 越大的 proposal,回归后提升越来越不明显,虽然精度没有下降。再看 u=0.7,对于低质量 proposal,其提升较少,这主要因为低质量的 proposal 被滤掉,没有得到训练,但是对于高质量 的bbox,提升较大。
可以发现,Input IoU 在 0.55~0.6 范围内 proposal 阈值设置为 0.5 时 detector 性能最好,在 0.6~0.75 阈值为 0.6 的 detector 性能最佳,而到了 0.75 之后就是阈值为 0.7 的 detector 性能最好了。只有输入 proposal 自身的 IoU 分布和 detector 训练用的阈值 IoU 较为接近的时候,detector 性能才最好,或者说阈值 IoU 设置应该和 R-CNN 训练的输入样本 IoU 分布接近的时候,性能最好,如果两个阈值相距比较远就是 mismatch 问题。
上图(d),在 IoU=0.5~0.6 的时候,检测性能下降比较少,但是一旦 IoU=0.7,检测性能就非常差了。这说明不能一味的提高 IoU 来达到输出高质量 bbox 的目的(对应匹配正样本数目不够,会出现过拟合)。
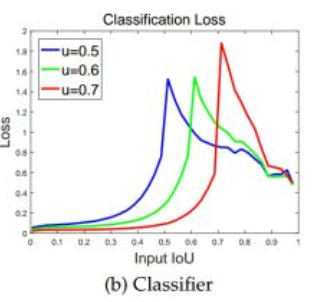
上图 (b),其在当前设定的 IoU 阈值处分类 loss 会存在一个峰值。假设 IoU 阈值为 0.5,那么 proposal 与 gt bbox 值的 IoU 在大于 0.5 时候是正样本,低于 0.5 是背景样本,决策边界其实就在 0.5 附近了,那自然在分隔带上的 loss 最大。假设一个二分类问题,大于 0 是正样本,小于 0 是负样本,分类目的就是尽可能把 0 附近的正负样本区分开(对于正样本,预测 0 要变成预测 1,对于负样本,预测 0 要变成预测 -1,那自然 loss 最大),此时靠近 0 附近的样本 loss 肯定最大,梯度也是最大的。
2. Cascade R-CNN 网络结构
既然单一阈值会带来mismatch的问题,那么级联多个detector,形成一个multi-stage的detector结构,然后每一个stage都有一个不同的IoU阈值,从而达到提升检测效果的目的。
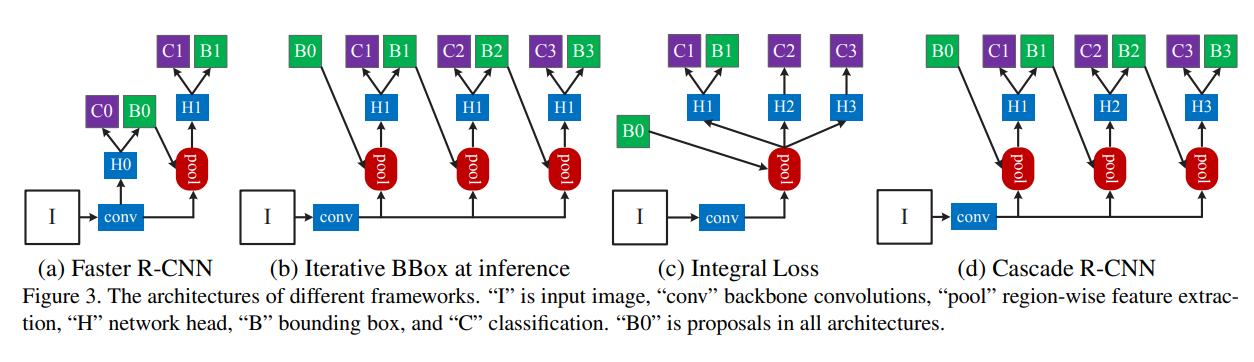
- 图(a) 是标准的 Faster R-CNN 结构,属于二级 bbox 回归
- 图(b) 是前向时候不断迭代 bbox 回归,训练时候还是和 Faster R-CNN 一样
- 图(c) 是对分类概率进行多次分类,使用了不同的阈值来进行分类,然后融合他们的结果进行分类推理,并没有同时进行 bbox 回归
- 图(d)则为Cascade-RCNN的网络架构,该结构可以保证训练和测试流程完全一样,一致性更强
Iterative BBox方法的三个detector的H共享,且每个分支的IoU阈值都设置为0.5,单一阈值的无法对所有proposal取得不错的回归效果。另外,各分支的detector也会相应的改变proposals的分布,沿用一个阈值的话,后边的detector的训练样本就会包含较多的离群点(outliers),使用共享的H也无法适应不同detector的输入变化。而Cascade-RCNN每个detector设置不同的阈值,可以跟好的消除离群点,适应新的proposal分布。
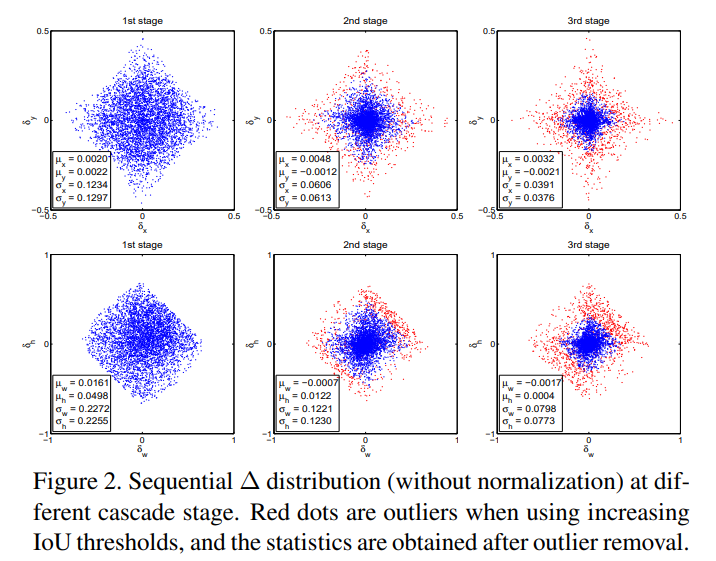
第一行横纵轴分别是回归目标中 bbox 的 x 方向和 y 方向偏移量;第二行横纵轴分别是回归目标中 bbox 的宽、高偏差量。可以看到,从 1st stage 到 2nd stage,proposal 的分布其实已经发生很大变化了,因为很多噪声样本经过 bbox 回归后实际上也提高了 IoU,2nd 和 3rd 中的那些红色点已经属于 outliers,如果不提高阈值来去掉它们,就会引入大量噪声干扰,对结果很不利。从这里也可以看出,阈值重新选取本质上是一个 resample 过程,它保证了样本质量。
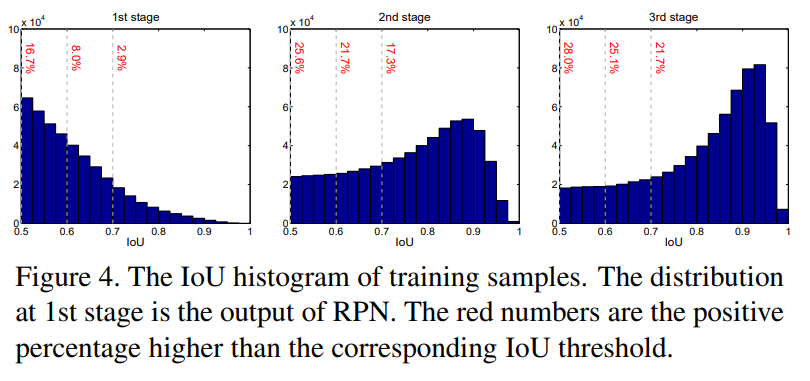
但是如果不断提高IoU阈值,会不会导致后续正样本越来越少,从而也有过拟合的风险? 作者也做了大量实验,如下图所示,可以看出,样本不仅没有减少,而且稍稍有增加。说明本文方法不会减少正样本数量,是有效的。并且可以发现各个阶段那个 IoU 的 bbox 分布最多。所以级联多个 R-CNN 模块,并且不断提高 IoU 阈值,在每个阶段不断进行正负样本重采样策略,不仅不会出现过拟合,而且可以实现极大的性能提升。
3. 训练流程及推理流程
Cascade-RCNN在代码层面实现是在 Faster R-CNN 后面再级联 n 个 R-CNN,每个 R-CNN 的输入都是前一个 R-CNN 的检测输出。在训练时,相比 Faster R-CNN, 其对每个 stage 都单独设置了各自的 bbox_assigner 和 bbox_sampler,同时多了一个 refine_bboxes 过程。
Cascade R-CNN 测试流程需要注意的是:最终的分类分值不是最后一个 stage 输出,而是 n 个 stage 的平均值,但是 bbox 预测值是最后一个 stage 输出。