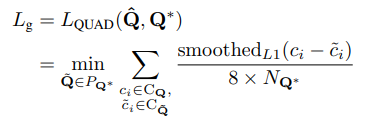1. EAST
EAST: An Efficient and Accurate Scene Text Detector
paper : https://arxiv.org/pdf/1704.03155.pdf
code:
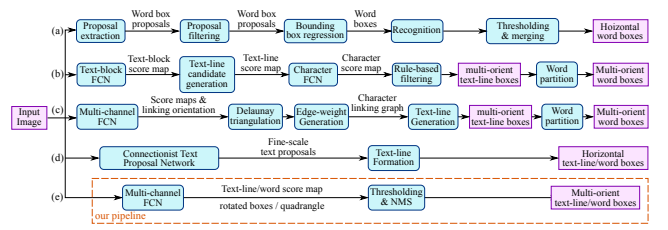
EAST算法整体框架如下图(e)所示, 第一个阶段是一个全卷积网络,结合了Unet的跨层特征聚合操作,直接输出文本框的预测,第二个阶段是对生成的文本预测框(旋转矩形或者矩形)通过NMS输出最终结果。
核心思想:
- 提出两阶段的文本检测方法:全卷积网络(FCN)和非极大值抑制(NMS),消除中间过程冗余,减少检测时间。
- EAST可以检测单词级别,又可以检测文本行级别.检测的形状可以为任意形状的四边形。
- 采用了Locality-Aware NMS来对生成的几何进行过滤。
2. Pipeline
EAST结合了DenseBox和Unet网络中的特性,整体算法流程如下图所示:
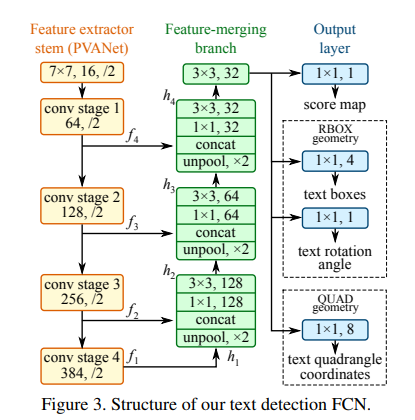
1. Feature Extractor : 采用通用的CNN网络,例如VGG,ResNet等作为主干网络,提取特征。
2. Feature-Merging: 采用类似Unet的结构,将主干网络不同level的特征图进行聚合,采用的是 UnPooling+Conv的结构,主要是解决文本行尺度变化大的问题。Early stage可以预测小的文本行,Late stage可以预测大的文本行。
3. Output: 网络输出主要包含文本得分和文本形状相关信息的预测信息,不同文本形状(RBOX、QUAD),网络输出也有区分。
* 对于旋转框,输出文本得分图+ AABB boundingbox(相对于top、right、bottom、left)的偏移 + rotate angle旋转角度 (1 + 4 + 1)。
* 对于矩形框,输出文本得分图+ 四个顶点相对于pixel location的坐标偏移 (1 + 8)。
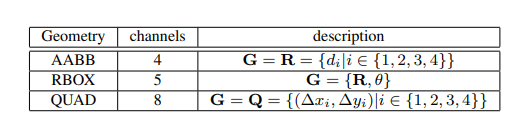
3. 训练标签设置
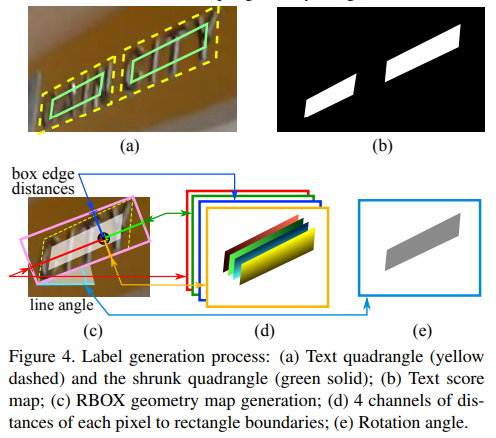
其中,RBOX的几何形状由4个通道的水平边界框(AABB)R和1个通道的旋转角度θ表示;AABB 4个通道分别表示从像素位置到矩形的顶部,右侧,底部,左侧边界的4个距离;QUAD使用8个数字来表示从矩形的四个顶点到像素位置的坐标偏移,由于每个距离偏移量都包含两个数字(Δxi;Δyi),因此几何形状输出包含8个通道。
score map 上QUAD的正面积为原图矩形区域的缩小版,如上图(a)(b)。
Box几何位置的确定,很多数据集(如ICDAR2015)是用QUAD的方式标注的,首先生成以最小面积覆盖区域的旋转矩形框。每个像素有一个正的分数值,我们计算它与文本框四边的距离,把它们放入四通道的RBOX 真值中, 如上图(c,d,e)。对于QUAD真值,8通道几何形状图每个像素的正分数值是它与四边形4个顶点的坐标偏移。
4. Loss
loss由两部分构成,score map loss 和 geometry loss, 具体的参数含义请参考论文:
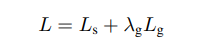
其中,分数图损失采用类平衡交叉熵损失,用于解决类别不平衡问题。
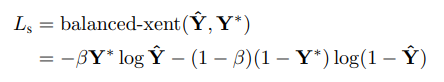
其中,几何参数损失分两种情况
针对旋转几何参数,采用IOU损失
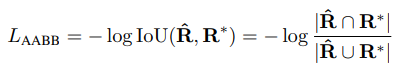
针对矩形几何参数,采用Smooth L1损失