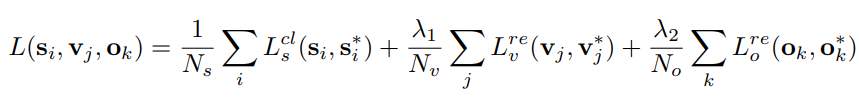CTPN文本检测算法
不同于自然界的其他单独物体,例如行人,物品等,文本信息蕴含更多的序列信息,文本可以由”单个字符、字符的一部分、多个字符”组织成一个sequence,文本目标不像行人 或者物体这种普通目标具有独立,封闭的范围。所以在目标检测算法中融入循环神经网络(RNN, LSTM),利用上下文信息进行文本检测是一个不错的方法。
文本检测相较于一般的目标检测,主要有以下几种区别:
- 文本信息边界不易确定, 例如单词内的空格与单词间的空格会导致文本的边界范围不清晰。
- 文本信息蕴含序列特征,上下文的序列信息有助于文本检测。
- 文本行的长度变化范围较大,相比如普通物体的尺度信息,普通检测算法难以生成质量好的Region Proposal(或者称为 Text Proposal)。

上图展示了用Faster-RCNN网络和CTPN的检测效果,可以看到通用的目标检测算法的检测框会偏移较多,且对文本信息的边界定义比较模糊,而CTPN算法要准确的多。
CTPN的整体架构如下图所示:
- 采用VGG-16作为检测网络的BackBone,下采样16倍后在Conv5之后提取空间特征信息,输出维度为B × W × H × C;
- 在Conv5的特征图上进行3x3xC的卷积,输出维度仍为B × W × H × C,这一步中的每一个特征点都融合了周围3 × 3的信息。(原始论文中采用的caffe的img2col进行特征的Reshape,这里采用3x3xC卷积代替,pytorch/tensorflow框架下的实现)。
- 接着将B × W × H × C维度的特征Reshape为(BH) × W × C的特征,然后作为双向LSTM的输入提取每一行的的序列特征,最后输出特征维度为(BH) × W × 256,然后Reshape至B x 256 x H x W。
- 经过FC,输出B x H x W x 512。
- N × H × W × 512 最后会经过一个类似RPN的网络,分成三个预测支路:如上图所示,其中一个分支输出N × H × W × 2k,这里的k指的是每个像素对应k个anchor,这里的2K指的是对某一个anchor的预测;第二个分支输出N × H × W × 2k,这里的2K指的是2K个前景背景得分,记做。最后一个分支输出N × H × W × k,这里是K个side-refinement,预测某个anchor预测
![[公式]](/images/OCR-CTPN%E7%AE%97%E6%B3%95%E9%9A%8F%E8%AE%B0/equation.svg+xml)
- RPN之后会输出类似下图b中的text proposal, 然后适用NMS进行过滤。
- 后处理,使用文本线构造方法合成一个完成的文本行,同时矫正倾斜的情况。
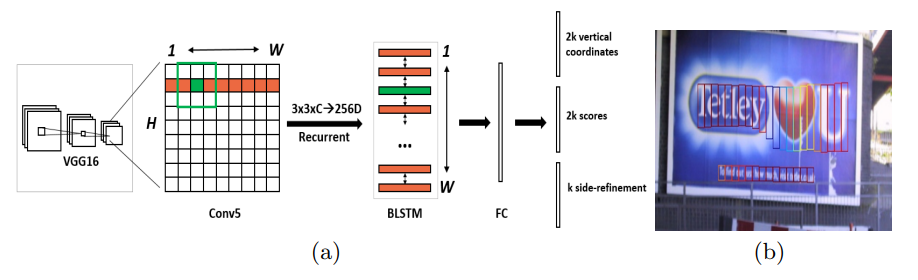
双向LSTM
VGG16提取的是空间特征,而LSTM学习的就是序列特征,而这里使用的是双向LSTM,更好的避免RNN当中的遗忘问题,更完整地提取出序列特征。
Text Proposal生成
文本长度的剧烈变化是文本检测的挑战之一,作者认为文本在长度的变化比高度的变化剧烈得多,文本边界开始与结束的地方难以和Faster-rcnn一样去用anchor匹配回归,所以作者提出一种vertical anchor的方法,即我们只去预测文本的竖直方向上的位置,不去预测水平方向的位置,水平位置的确定只需要我们检测一个一个小的固定宽度的文本段,将他们对应的高度预测准确,最后再将他们连接在一起,就得到了我们的文本行,如下图所示:

对于每个像素点设置的anchor的宽度都是固定的,为16像素(原图),对应到特征图上就为1个像素(下采用了16倍)。而高度则是从11到273变化,这里我们每个像素点取k=10个anchor。
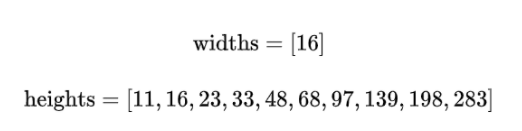
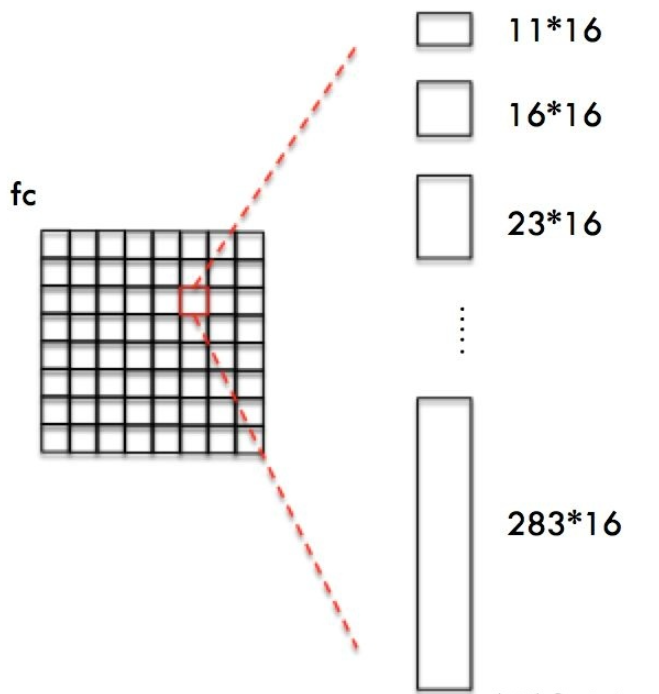
这样设置Anchors是为了:
- 保证在 x方向上,Anchor覆盖原图每个点且不相互重叠。
- 不同文本在 y 方向上高度差距很大,所以设置Anchors高度为11-283,用于覆盖不同高度的文本目标。
获得Anchor后,与Faster R-CNN类似,CTPN会做如下处理:
- Softmax判断Anchor中是否包含文本,即选出Softmax score大的正Anchor
- Bounding box regression修正包含文本的Anchor的中心y坐标与高度。
因为宽度是固定的,所以只需要anchor的中心的y坐标以及anchor的高度就可以确定一个anchor,其中带星号的为ground-truth,没有带星号的则是预测值,带a的则是对应anchor的值。
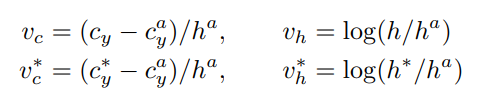
RPN层
CTPN的RPN层和Faster R-CNN很像,
第一个分支输出的是anchor的位置,也就是anchor的两个参数,因为每个特征点配置10个anchor,所以这个分支的输出20个channel。
第二个分支则是输出前景背景的得分情况(text/non-text scores),通过softmax计算得分,所以这里也是输出20个channel。
第三个分支则是输出最后水平精修side-refinement的比例o,这是由于每个anchor的宽是一定的,所以有时候会导致水平方向有一点不准,所以这时候就需要校准一下检测框。
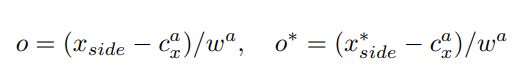
Xside标识检测框的左边界或者右边界,Cx 表示anchor中心的横坐标。Wa是anchor固定的宽度16个像素。可以把这个o理解为一个缩放的比例,来对最后的结果做一个准确的拉伸,下面这张图中红色的就是使用了side-refinement,黄色的则是没有使用的结果。

文本线构造方法
经过RPN之后生成一串或者多串text proposal , 然后用文本线构造办法,把这些text proposal连接成一个文本检测框。
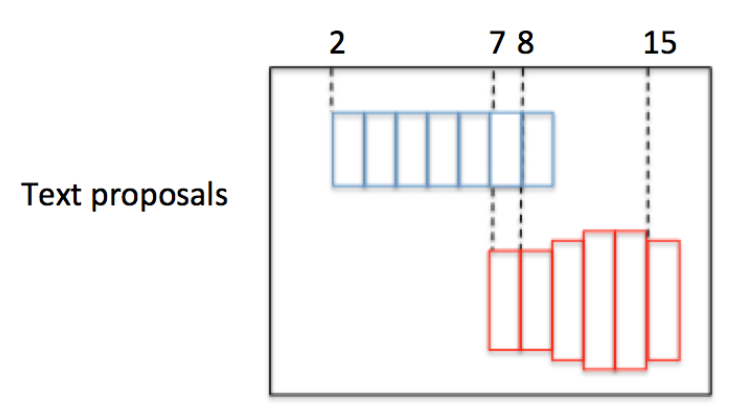
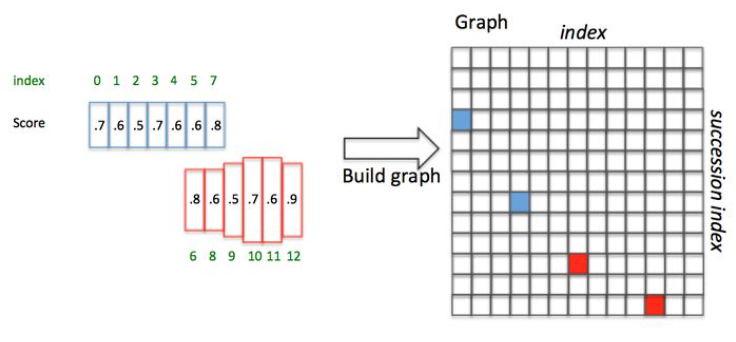
为了说明问题,假设某张图有上图所示的2个text proposal,即蓝色和红色2组Anchor,CTPN采用如下算法构造文本线:
- 按照水平 x 坐标排序Anchor
- 按照规则依次计算每个Anchor 的 ,组成
- 通过建立一个Connect graph,最终获得文本检测框。
文本线构造算法通过如下方式建立每个Anchor 的 :
- 正向寻找:
- 沿水平正方向,寻找和box_i水平距离小于50像素的候选Anchors(每个Anchor宽16像素,也就是最多正向找50/16=3个)
- 从候选Anchor中,挑出与box_i竖直方向 的Anchor
- 挑出符合条件2中Softmax Score最大的box_j
- 反向寻找
- 沿水平负方向,寻找和box_j水平距离小于50像素的候选Anchors
- 从候选Anchor中,挑出与box_j竖直方向 的Anchor
- 挑出符合条件2中Softmax Score最大的box_k
- 对比score_i 和 score_j:
- 如果 ,则说明这是一个长连接,则设置Graph(i,j) = True;
- 如果, 则说明这不是一个最长的连接(即该连接肯定包含在另外一个更长的连接中)。
Loss
CTPN的损失函数如下图,分为三个部分:
(1) LS:每个anchor是否是正样本的classification loss
(2) Lv:每个anchor的中心y坐标和高度loss
(3) L0:文本区域两侧精修的x损失
和Faster-RCNN一样,以上的loss都采用smooth L1 loss。