转载自:计算机视觉Daily,个人学习记录
1. 简介
AdaFocus为被ICCV-2021会议录用为Oral Presentation的一篇文章:Adaptive Focus for Efficient Video Recognition。 其从空间特征角度出发,从降低空间冗余性来实现高效视频识别。
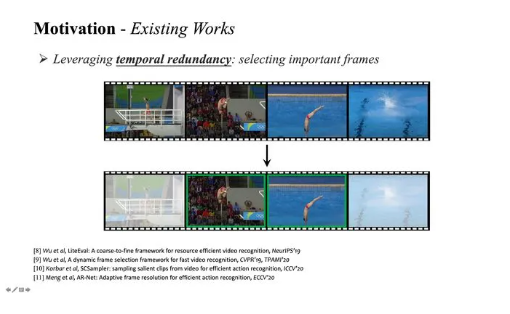
现有高效视频识别算法往往关注于降低视频的时间冗余性(即将计算集中于视频的部分关键帧),如图1 (b)。本文则发现,降低视频的空间冗余性(即寻找和重点处理视频帧中最关键的图像区域),如图1 (c),同样是一种效果显著、值得探索的方法;且后者与前者有效互补(即完全可以同时建模时空冗余性,例如关注于关键帧中的关键区域),如图1 (d)。在方法上,本文提出了一个通用于大多数网络的AdaFocus框架,在同等精度的条件下,相较AR-Net (ECCV-2020)将计算开销降低了2.1-3.2倍,将TSM的GPU实测推理速度加快了1.4倍。

- 论文:https://arxiv.org/pdf/2105.03245.pdf
- Code:https://github.com/blackfeather-wang/AdaFocus
- B站介绍:https://www.bilibili.com/video/BV1vb4y1a7sD/
- 作者个人网站:https://www.rainforest-wang.cool/
2. 研究动机
相较于图像,视频识别是一个分布范围更广、应用场景更多的任务。如下图所示,每分钟,即有超过300小时的视频上传至YouTube;至2022年,超过82%的消费互联网流量将由在线视频组成。自动识别这些海量视频中的人类行为、事件、紧急情况等内容,对于视频推荐、监控等受众广泛的实际应用具有重要意义。

近年来,已有很多基于深度学习的视频识别算法取得了较佳的性能,如TSM、SlowFast、I3D等。然而,一个严重的问题是,相较于图像,使用深度神经网络处理视频通常会引入很大的计算开销。如下图所示,将ResNet-50应用于视频识别将使运算量(FLOPs)扩大8-75倍。

因此,一个关键问题在于,如何降低视频识别模型的计算开销。一个非常自然的想法是从视频的时间维度入手:一方面,相邻的视频帧之间往往具有较大的相似性,逐帧处理将引入冗余计算;另一方面,并非全部视频帧的内容都与识别任务相关。现有工作大多从这一时间冗余性出发,动态寻找视频中的若干关键帧进行重点处理,以降低计算成本,如下图所示。
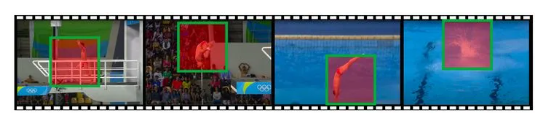
但是,值得注意的一点是,我们发现,目前尚未有工作关注于视频中的空间冗余性。具体而言,在每一帧视频中,事实上只有一部分空间区域与识别任务相关,例如下图中的运动员、起跳动作、水花等。
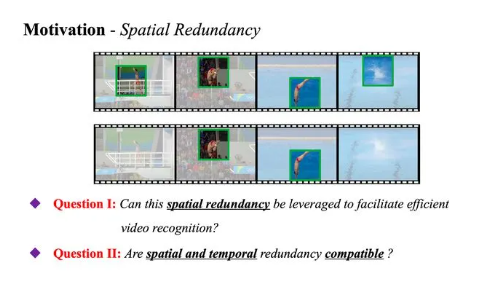
出于这一点,本文以回答图6中的两个问题作为主线:
- 空间冗余性是否可以用于实现高效视频识别?假如我们能找到每一视频帧中的关键区域,并将主要的计算集中于这些更有价值的部分,而尽可能略过其他任务相关信息较少的区域,理论上,我们就可以显著降低网络的计算开销(事实上,我们之前基于单张图像验证过类似做法的效果:NeurIPS 2020 | Glance and Focus: 通用、高效的神经网络自适应推理框架:https://zhuanlan.zhihu.com/p/266306870)。
- 空间、时间冗余性是否互补?若上述假设成立的话,它应当可与现存的、基于时间冗余性的工作相结合,因为我们完全可以先找到少数关键帧,再仅在这些帧中寻找关键的图像区域进行重点处理。
3. 核心思想
首先为了回答问题1,作者设计了一个AdaFocus框架,其结构如下图所示。
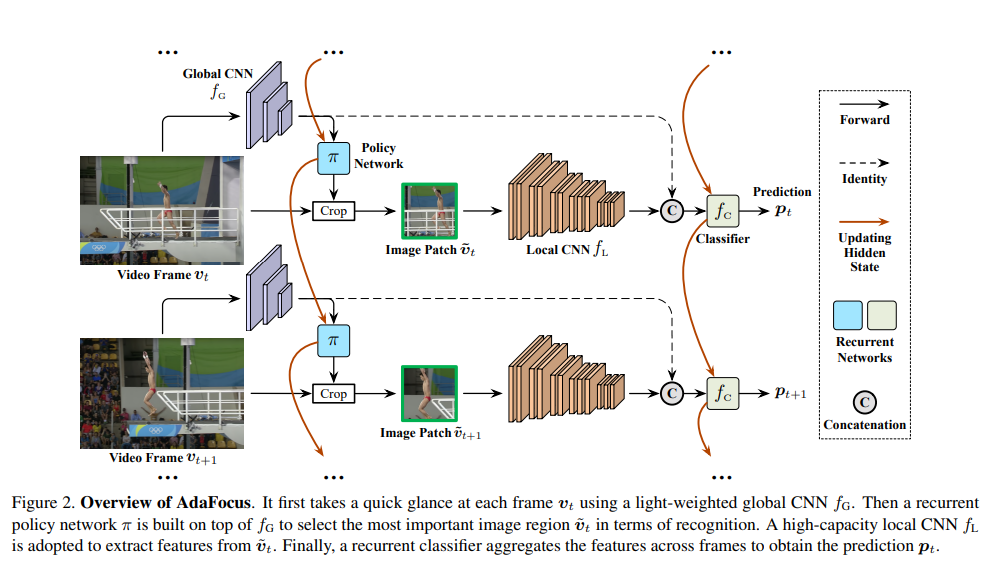
此处我们假设视频帧按时间次序逐个输入网络,AdaFocus使用四个组件对其进行处理。
- 全局CNN (Global CNN)是一个轻量化的卷积网络(例如MobileNet-V2),用于以低成本对每一帧视频进行粗略处理,获取其空间分布信息。
- 策略网络 (Policy Network)是一个循环神经网络(RNN),以的提取出的特征图作为输入,用于整合到目前为止所有视频帧的信息,进而决定当前帧中包含最重要信息的一个图像小块(patch)的位置。值得注意的是由于取得patch的crop操作不可求导,是使用强化学习中的策略梯度方法(policy gradient)训练的。
- 局部CNN(Local CNN)是一个容量大、准确率高但参数量和计算开销较大的卷积网络(例如ResNet),仅处理策略网络 选择出的局部patch,由于patch的空间尺寸小于原图,处理其的计算开销显著低于处理整个视频帧。
- 分类器(Classifier)为另一个循环神经网络(RNN),输入为和 输出特征的并联,用于整合过去所有视频帧的信息,以得到目前最优的识别结果(t表示帧序号)。
4. 主要贡献点
(1)在现有的基于时间冗余性的方法之外,思考利用空间冗余性实现高效视频识别;
(2)基于强化学习,提出了一种在理论上和实测速度上效果都比较明显的通用框架,AdaFocus;
(3)在五个数据集上进行了实验,包括与其他通用框架的比较和部署于现有高效识别网络(例如TSM)上的效果等。