1. 简介
深度学习在具体的商业落地场景中需要依赖于海量的数据。算法,算力,数据是驱动Deep Learning 运行的三大动力, 而数据又是其中重要影响因素,模型效果80%靠数据,20%靠算法。在工业场景中,面对众多非标准化产品,频繁更换型号的场景,进行数据标准的成本是巨大的,而且客户对某一款产品的算法落地时间有限制, 且如果模型对相似型号的兼容性较差,也会引起客户对AI方案的不信任。
在此种背景下,如何利用大量未标注的图像以及部分已标注的图像来提高模型的性能就变得尤为重要。其中,半监督学习(SSL)就是一种值得尝试的方案,Fix-Match, 是谷歌Google Brain 提出的一种半监督学习方法,对于解决数据收集困难,标注成本高的CV问题会有一定的帮助。
- FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- 主要贡献: 利用一致性正则化( Consistency regularization)和伪标签(pseudo-labeling)技术进行无监督训练。SOTA 精度,其中CIFAR-10有250个标注,准确率为94.93%。甚至仅使用10张带有标注的图在CIFAR-10上达到78%精度。
- 论文: https://arxiv.org/abs/2001.07685
- code: https://github.com/google-research/fixmatch
2. 半监督学习
半监督学习(Semi-supervised learning)是一种学习方法,其使用少量标记的数据和大量未标记的数据进行学习。相对于监督学习(Supervised Learning)而言,最大的优势是无需为所有数据准备标签。
FixMatch使用的数据集也为带所有标注的数据集,如CIFAR-10, 因为算法训练的要求,需要姜训练数据中的一部分标签删掉, 换句话说,其训练数据为一部分有标签数据 + 一部分无标签数据。
3. 核心思想
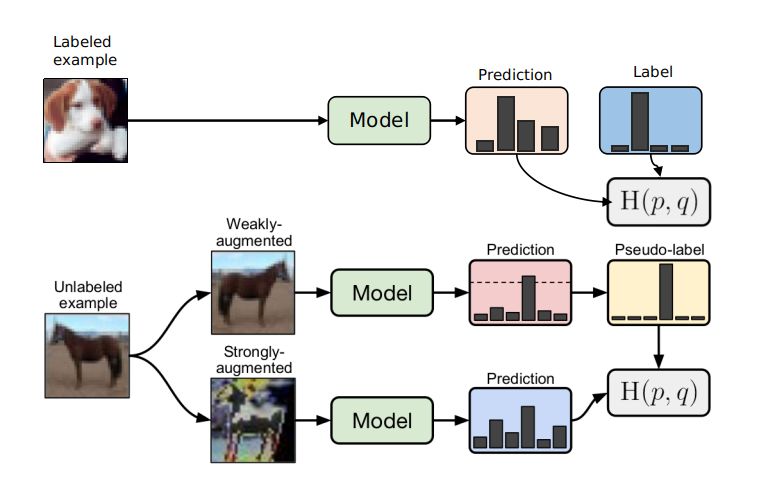
- 整体分为两个部分, 有监督训练部分和无监督训练部分。
- 监督训练部分, 利用labeled数据进行监督训练,得到Model A
- 无监督训练部分, 首先由原图生成弱增强数据,通过Model A获得伪标签(pseudo-label), 然后使用交叉熵损失利用该伪标签去监督强增强的输出值, 特别地,FixMatch仅使用具有高置信度的未标记样本参与无监督训练部分。
- 无监督训练部分包含两种策略,一致性正则化及伪标签训练。
- 一致性正则化是当前半监督SOTA工作中一个重要的组件,其建立在一个基本假设:相同图片经过不同扰动(增强)经过网络会输出相同预测结果,FixMatch是对弱增强图像与强增强图像之间的进行一致性正则化,但是其没有使用两种图像的概率分布一致,而是使用弱增强的数据制作了伪标签,这样就自然需要使用交叉熵进行一致性正则化了。
- 伪标签是利用模型本身为未标记数据获取人工标签的思想。通常是使用“hard”标签,也就是argmax获取的onehot标签,仅保留最大类概率超过阈值的标签。
3. Why Work ?
无监督训练过程实际上是一个孪生网络,可以提取到图片的有用特征。弱增强不至于图像失真,再加上输出伪标签阈值的设置,极大程度上降低了引入错误标签噪声的可能性。而仅仅使用弱增强可能会导致训练过拟合,无法提取到本质的特征,所以使用强增强。强增强带来图片的严重失真,但是依然是保留足够可以辨认类别的特征。有监督和无监督混合训练,逐步提高模型的表达能力。
4. 细节
- 数据增强方式
- 弱增强:用标准的翻转和平移策略, 50%的概率进行flip和12.5%的概率进行shift,包括水平和竖直方向。
- 强增强:输出严重失真的输入图像,先使用RandAugment 或 CTAugment,再使用 CutOut 增强
- 网络模型
- FixMatch使用 Wide-Resnet 变体作为基础体系结构,记为 Wide-Resnet-28-2,其深度为 28,扩展因子为 2。因此,此模型的宽度是 ResNet 的两倍。
- 算法流程

(1)Input:准备了batch=B的有标签数据和batch=μB 的无标签数据,其中μ是无标签数据的比例;
(2)监督训练:对于在标注数据的监督训练,将常规的交叉熵损失 H()用于分类任务。有标签数据的损失记为ls,如伪代码中第2行所示;
(3)生成伪标签:对无标签数据分别应用弱增强和强增强得到增强后的图形,再送给模型得到预测值,并将弱增强对应的预测值通过 argmax 获得伪标签;
(4)一致性正则化:将强增强对应的预测值与弱增强对应的伪标签进行交叉熵损失 H()计算,未标注数据的损失由 lu 表示,如伪代码中的第7行所示;式τ表示伪标签的阈值;
(5)完整损失函数:最后,我们将ls和lu损失相结合,如伪代码第8行所示,对其进行优化以改进模型,其中,λu 是未标记数据对应损失的权重。
5. 实验结果
作者分别在CIFAR和SVHM等数据集上进行了训练测试,模型表现超过之前的网络。具体如下:
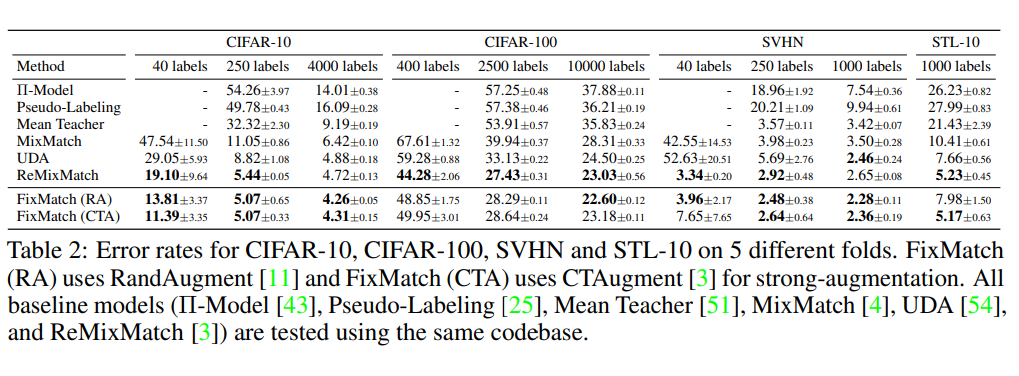
- 对于极端缺少标注的场景,仅仅使用每个类别1张共10张标注的图片就可以达到78%的最大accuracy,当然这种做法和挑选的样本质量有关,作者也做了相关实验论证。不过也证明本文的方法的确work。

另外还有一些具体的调参实验,总的来说,通过FixMatch,我们可以得到以下结论:
(1)使用具有高置信度的未标记数据参与训练效果比较好(Argmax);
(2)适当增加batch中未标记数据的比例有助于提高识别精度;
(3)T越小(即分布越尖锐),则精度会越高(Sharppen Method)。
总的来说,半监督学习是一种好方法,因为其是一种可以在开始高成本之前使用的方法。
Reference
- FixMAtch是半监督领域的一篇经典论文,其做法简单有效,使用图像增强技术进行伪标签学习和一致性正则化训练,在CIFAR等多个数据集上仅仅利用少量的标注图片就可以达到一个不错的效果,这对于获取标注困难的场景非常有意义。例如在工业应用领域,可能会有海量数据,但是现实限制可能无法都进行人工标注,因此可以尝试利用半监督训练的方法,非常值得借鉴。
- https://zhuanlan.zhihu.com/p/165337501
- https://zhuanlan.zhihu.com/p/422930830
- https://zhuanlan.zhihu.com/p/340474319
个人记录学习