前言
记得刚工作的时候做摄像头端的灯语识别, 主要是未涂红状态下的各种信号灯的识别, 当时用一个resnet-50跑了下实验觉得还不错, 结果导师讲用不了这么“大”的模型, 让把这个大模型砍成一个小的, 似懂非懂,一顿操作, 换backbone,各种轻量级网络,shuffleNet,mobilenet一顿尝试,还不如直接把resnet砍几层好使, 在此学习记录下田子宸@知乎的文章。
一 、模型”大小”评价指标
| 计算量 | 参数量 |访存量 |内存占用|
计算量
计算量是模型所需的计算次数,反映了模型对硬件计算单元的需求。计算量一般用 OPs (Operations) ,即计算次数来表示。由于最常用的数据格式为 float32,因此也常常被写作 FLOPs (Floating Point Operations),即浮点计算次数。
之前总结过卷积中的计算量 计算量。
参数量
参数量是模型中的参数的总和,跟模型在磁盘中所需的空间大小直接相关。对于 CNN 来说参数主要由 Conv/FC 层的 Weight 构成。
参数量往往是被算作访存量的一部分,因此参数量不直接影响模型推理性能。但是参数量一方面会影响内存占用,另一方面也会影响程序初始化的时间。
访存量 (MACs memory access cost)
访存量往往是最容易忽视的评价指标,但其实是现在的计算架构中对性能影响极大的指标。
访存量是指模型计算时所需访问存储单元的字节大小,反映了模型对存储单元带宽的需求。访存量一般用 Bytes(或者 KB/MB/GB)来表示,即模型计算到底需要存/取多少 Bytes 的数据。
和计算量一样,模型整体访存量等于模型各个算子的访存量之和。对于 Eltwise Sum 来讲,两个大小均为 (N, C, H, W) 的 Tensor 相加,访存量是 (2 + 1) x N x C x H x W x sizeof(data_type),其中 2 代表读两个 Tensor,1 代表写一个 Tensor;而对于卷积来说,访存量公式为:
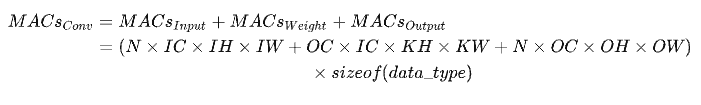
内存占用
内存占用是指模型运行时,所占用的内存/显存大小。一般有工程意义的是最大内存占用,当然有的场景下会使用平均内存占用。这里要注意的是,内存占用 ≠ 访存量。
和参数量一样,内存占用不会直接影响推理速度,往往算作访存量的一部分。但在同一平台上有多个任务并发的环境下,如推理服务器、车载平台、手机 APP,往往要求内存占用可控。可控一方面是指内存/显存占用量,如果占用太多,其他任务就无法在平台上运行;另一方面是指内存/显存的占用量不会大幅波动,影响其他任务的可用性。
二、计算量越小,模型推理越快吗?
答案是否定的。
实际上计算量和实际的推理速度之间没有直接的因果关系。计算量仅能作为模型推理速度的一个参考依据。
模型在特定硬件上的推理速度,除了受计算量影响外,还会受访存量、硬件特性、软件实现、系统环境等诸多因素影响,呈现出复杂的特性。因此,在手头有硬件且测试方便的情况下,实测是最准确的性能评估方式。
在设计网络结构时,如果有实测的条件,建议在模型迭代早期对性能也进行测试。一些 NAS 的方法也会对搜索出来的网络结构进行测速,或者干脆对硬件速度进行了建模,也作为初期搜索的重要参数。这种方法设计出来的网络在后期部署时,会极大减少因性能问题迭代优化的时间和人力开销。
这里作者讨论影响模型在硬件上推理速度的一些因素,一方面希望可以帮助手动/自动设计网络结构的同学更快的设计更高效的网络结构,另一方面希望当模型部署时性能出现问题时能够为大家提供分析原因的思路。
- 计算密度与 RoofLine 模型
- 计算密集型算子与访存密集型算子
- 推理时间
- 计算密度与 RoofLine 模型
计算密度是指一个程序在单位访存量下所需的计算量, 单位是FLOPs/Byte, 也称计算访存比,用于反映一个程序相对于访存来说计算的密集程度:
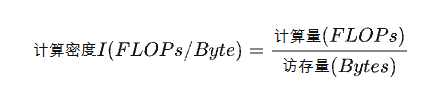
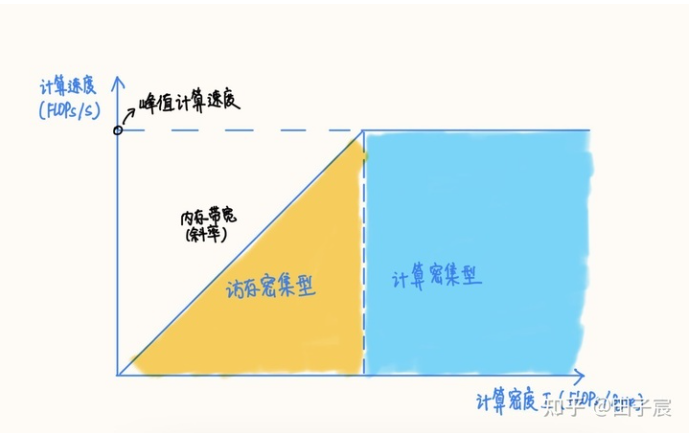
RoofLine 模型是一个用于评估程序在硬件上能达到的性能上界的模型,可用上图表示:
RoofLine 模型
用公式描述:
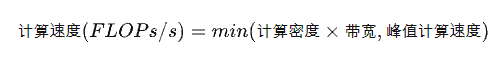
当程序的计算密度I较小时, 程序访存多而计算少,性能受到内存贷款限制,称为访存密集型程序。即上图的橙色区域,。在此区域上的程序性能上界 = 计算密度 * 内存带宽, 表现为图中的斜线,其中斜率为内存带宽的大小。计算密度越大, 程序所能达到的速度上界越高,但使用的内存带宽始终为最大值。